AV2 video codec
Published May 31, 2026.
Andrey Norkin is with NVIDIA.
The Alliance for Open Media (AOMedia) has officially published the AV2 specification. This marks a major milestone for AOMedia’s Video Codec Working Group (VCWG), which has dedicated more than five years to developing it. As a VCWG co-Chair throughout this process, alongside my fellow co-Chair Adrian Grange, I am proud to see this specification published and extend my congratulations to everyone who contributed to AV2.
This post provides an early look at what the new video codec specification brings to the global video ecosystem. For a deeper dive into AV2, stay tuned for future publications from the AOMedia members, which are coming soon.
AV2 represents the next generation of open video coding standards, arriving eight years after the publication of AV1, which is now widely implemented across TVs and other devices and used by major video content providers, such as YouTube, Meta, and Netflix.
To get started with the specification and the reference SW, you can use these resources:
- AV2 specification
- AV2 reference SW (AVM)
- Common Test Conditions (CTC) document (for configurations and command-line parameters)
The CTC document above would help you to configure the reference SW (AVM) in a way that produces good compression efficiency. If you would like to study compression performance achieved by AVM, do not rely on the software defaults, but use the suggested settings from the CTC document. For instance, settings suggested for the Random Access (RA) configuration would demonstrate results under the closed GOP with hierarchical bi-prediction and sub-GOP size of 16.
AV2 development
In 2020, the VCWG started exploration of video technologies beyond AV1. The exploration took place within the AOMedia Video Model (AVM) codebase, which evolved from libaom (AV1 reference SW) and later became the AV2 reference software.
The development of AV2 was based on contributions from AOMedia member companies under royalty-free commitment, and the codebase was publicly available from day one. The proposals were tested on the CTC and adopted if they advanced AV2 in terms of compression, supported features or reduced complexity. Better compression efficiency often comes at the expense of higher implementation complexity. To support efficient AV2 implementations, hardware experts from major decoder manufacturers actively reviewed algorithm implementations and provided feedback.
What AV2 brings to the video ecosystem
The new codec generations are expected to deliver substantially better compression, and AV2 excels here. Across multiple objective quality metrics, AVM demonstrates about 30% bitrate reduction at the same quality compared to AV1. The compression efficiency improvements hold across a wide range of resolutions, from 270p up to 4K. Some specialized content types — such as screen content and HDR — show even more gain. Finally, there is preliminary indication that the subjective quality gains are even higher than the ones from objective metrics. Comparisons with other specifications and subjective tests will likely appear soon, but at this moment, it is safe to assume that AV2 is the most efficient video compression specification nowadays.
Beyond compression efficiency, a video codec should seamlessly integrate into existing file formats and transmission protocols. Those aspects have been carefully considered throughout AV2 development. The placement of information and metadata relevant to the higher levels has been studied, and improvements made relative to the previous specifications.
In addition to that, AV2 supports applications beyond traditional rectangular video in a single bitstream. For instance, AR/VR headsets, such as Apple Vision Pro or Meta Quest require stereoscopic video. There is also an increased interest in multi-view TV applications with several video streams shown on the screen and applications that use alpha channel to perform composition of decoded video streams. Such applications, along with many other use cases, are supported by the AV2 specification. More examples of the supported applications are mentioned in the sections on core AV2 compression tools and tools supporting special use cases.
Fig. 1 illustrates the AV2 specification scope. Typically, video coding standards only define the decoder, with the conformance point being at the decoder output. This guarantees interoperability but allows flexibility and experimentation with encoder design and proprietary pre- and post-processing. AV2 follows this design but makes an exception for the film grain synthesis (FGS) tool, which is included in the normative part of AV2 to enable consistent film grain representation across AV2 devices, similarly to AV1. Additionally, AV2 adds native support for multiple sub-bitstreams.
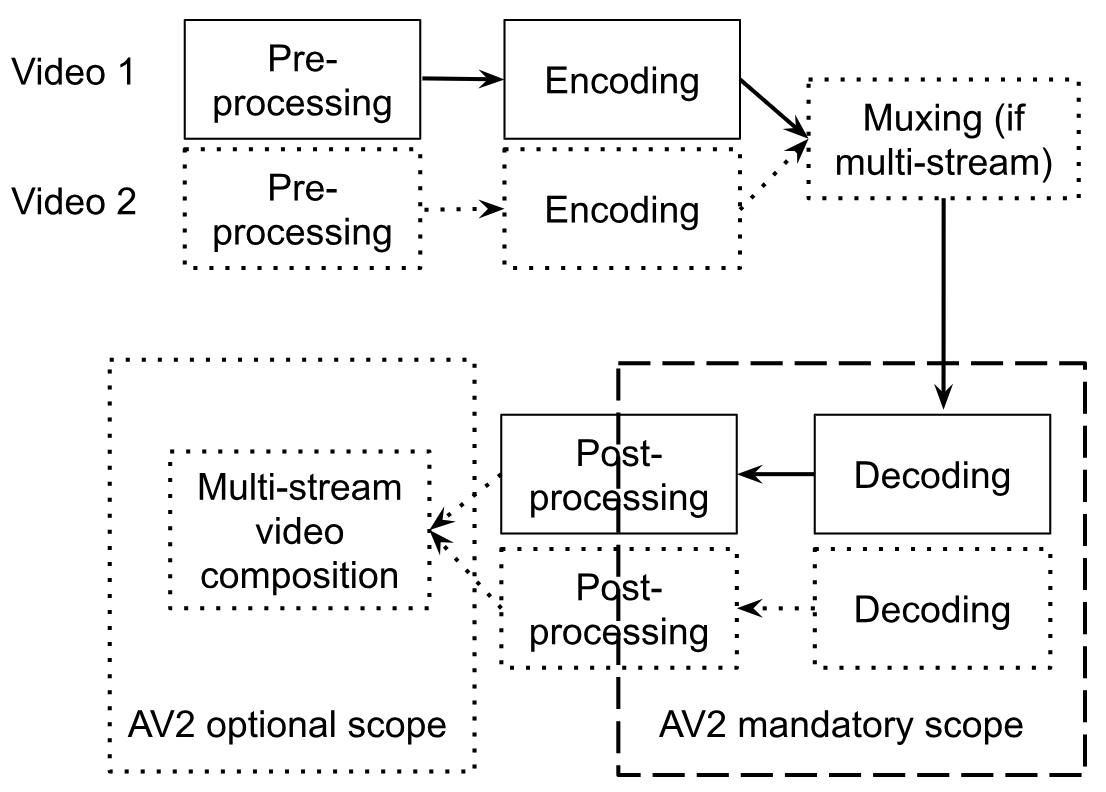
High-level AV2 architecture
Like previous generations of video codecs, AV2 relies on the hybrid video codec framework (see Fig. 2). An AV2 encoder may include a denoiser and FGS model analyzer. A frame is divided into rectangular blocks. A block can be predicted based on previously decoded samples of the same frame (intra-prediction), previous frame(s) (inter-prediction), or their combination. The prediction residual is transformed, and transform coefficients are quantized and encoded with an arithmetic encoder. The block modes and motion information are also encoded. Finally, film grain synthesis can be applied to the output frames.
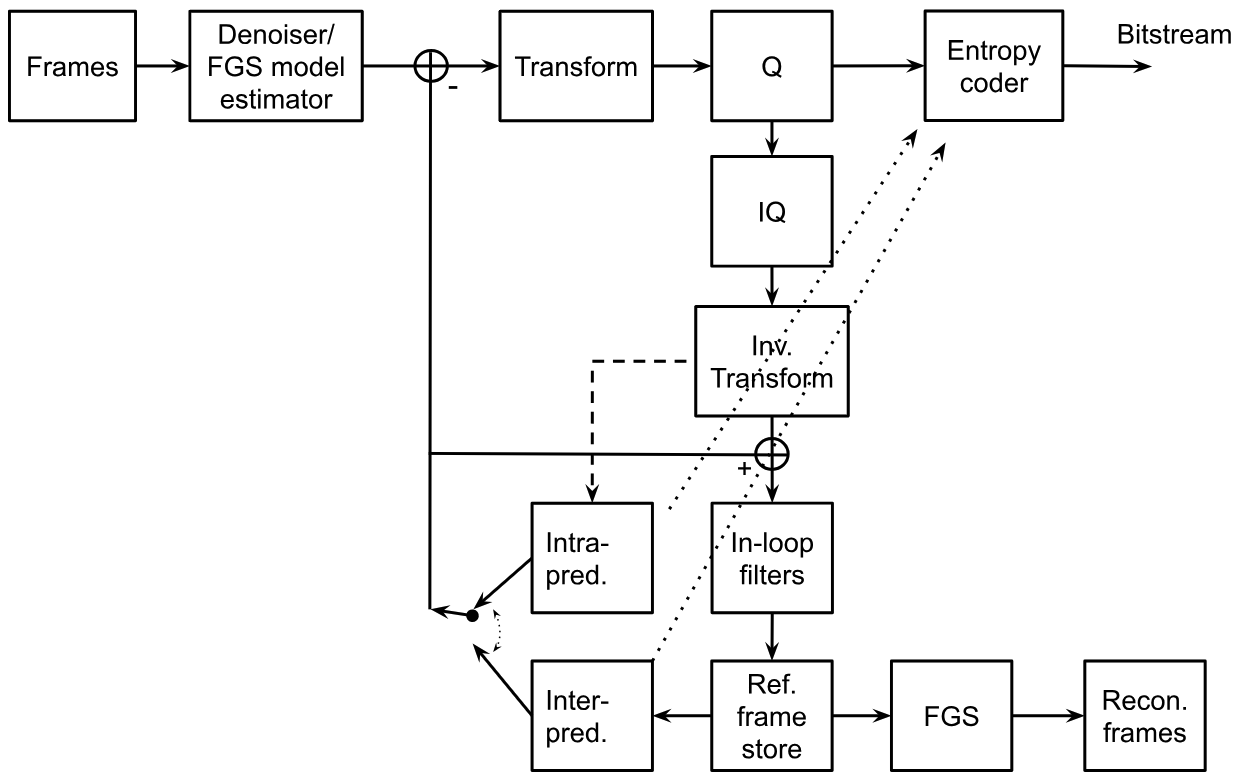
Core AV2 compression tools
While this post provides a brief overview, a more complete description of AV2 coding tools can be found here.
Video formats
AV2 supports main color representations but the specification has been developed primarily on YCbCr videos with 4:2:0 chroma subsampling at bit depths of 8 and 10. The specification also supports the 4:0:0, 4:2:2, and 4:4:4 formats at 8 and 10 bits, and performs competitively with those formats too. AV2 has been developed on the progressive scan material. However, interlaced video can be encoded with video fields represented by AV2 frames/pictures.
A frame in YCbCr 4:2:0 is represented by three rectangular arrays of dimensions H×W for luma and (H/2)×(W/2) for chroma. The chroma sample positions relative to the luma can vary depending on the color space, and the chroma position can be signaled in the Content Interpretations Open Bitstream Unit (CI OBU).
Superblocks and coding blocks
A frame is divided into non-overlapping superblocks (SB) of the same size of 256×256, 128×128 or 64×64 luma samples (with 256×256 SBs only allowed in inter-frames). Each superblock is a root of a coding tree recursively subdividing into smaller non-overlapping blocks, with the smallest possible block size of 4×4. The example of AV2 partitions is shown in Fig. 3.
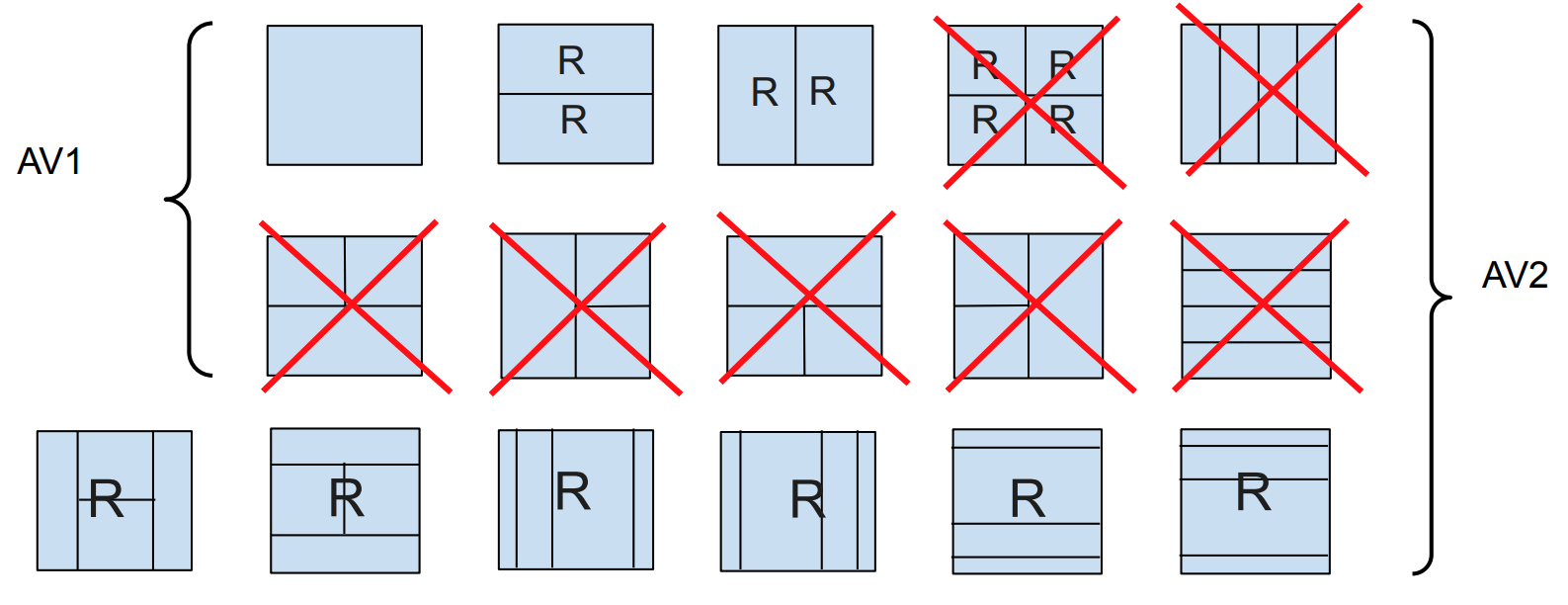
Intra-prediction
Intra-prediction uses decoded samples of the current frame. There are many intra-prediction modes, including directional prediction, DC prediction, smooth prediction, multiple reference line selection, and intra bi-prediction (IBP), where a block is predicted from two directions. Improved chroma from luma (CfL) tool and multi hypothesis cross component prediction (MHCCP) exploit the inter-component redundancy. The intra-block copy (IBC) is supported with local and global variants and, unlike in AV1, can be used together with in-loop filters. It makes this already very efficient screen content coding (SCC) tool even more useful, especially when encoding a mix of artificial and natural content. There is a data-driven approach with upscaled block predictions. The palette mode is also supported.
Inter prediction
Inter-prediction uses information from previously decoded frames. AV2 supports translational motion and affine motion models. There are several other tools, such as optical flow and sub-block motion refinement, that help increase accuracy of motion prediction. Temporal interpolated prediction (TIP) tool uses motion fields to generate a “virtual” frame at the current temporal position, at a frame or block level. Motion vectors (MVs) can be predicted from spatial neighbors and temporal neighbors, with complex motion trajectories supported. MV and warp prediction can also use MV banks and warp parameter banks. Finally, motion vector residuals may be coded at varying resolution.
Compound prediction
Compound prediction is based on two prediction hypotheses, including inter/inter and inter/intra predictions. AV2 has several approaches for combining two predictions, such as those with equal or unequal uniform weights, weights based on sample positions, such as wedge prediction, sample value differences, and other approaches to predict a block.
Transforms and quantization
Transforms pack residual energy into lower frequency coefficients. Similar to AV1, AV2 supports four primary 1‑D transform types that result in 16 2‑D combinations. Secondary transforms can be applied to low frequency coefficients. 64×64 transform residuals are obtained from a 32×32 residual by upscaling. Cross-chroma component transforms can further decorrelate chroma coefficients. AV2 supports scalar quantization (SQ) and trellis coded quantization (TCQ), where overlapping quantizers operate as a state machine to further improve coding efficiency. The quantization range in AV2 has been expanded compared to AV1, allowing encoders to reach lower bitrates.
Entropy coding
Quantized coefficients, motion data, and block modes are coded using multi-symbol arithmetic coding, which can use context modelling. Entropy coding uses more flexible adaptation and initialization strategies, as well as a smaller alphabet size than AV1, up to 8 symbols. Coefficient coding has been updated to improve throughput and efficiency.
In-loop filters and post-processing
AV2 has several in-loop filters. The deblocking in AV2 has been updated to better adapt to higher quantization and use of subsequent filters. In particular, the AV2 deblocking has been designed to avoid too much low-pass filtering (see Fig. 4). The CDEF was carried over from AV1. A cross-component sample offset (CCSO) and guided-detail filter (GDF) have been added, while the loop restoration (LR) filter has been significantly re-worked and the AV1 super-resolution tool removed. The filters are organized in three stages, with some filters working in parallel to allow more efficient implementations.
There is a film grain synthesis tool that can be applied to the output pictures, which is very similar to the one used in AV1, with some improvements to visual quality and coding of model parameters.
Tiles
For parallel processing, a frame can be partitioned into tiles. Superblocks in each tile are coded independently from other tiles, which makes it possible to encode and decode tiles independently.
Extended alt-ref and overlay frames
Alternative reference frames are a tool carried over from AV1. These frames are never displayed and only used for prediction. Typically, they undergo temporal filtering, which makes them better predictors for other frames. An overlay frame then uses its associated alt-ref frame as a predictor and adds fine details. AV2 extends this concept to key frames. A temporally filtered key frame is used as a predictor, while an overlay frame is used for the output. This makes is possible to use the key frame for prediction more efficiently, while preserving high-frequency details.
Frame reordering
Frame reordering allows the codec to use bi-prediction, which greatly improves coding efficiency. In AV1, frame reordering was implemented using a frame header with the show_existing_frame syntax element and a reference to a slot in the reference frame buffer. AV2 still supports this method of frame reordering. However, it also supports implicit output frames, which can be output later depending on their order_hint.
AV2 tools supporting special use cases
Flexible Random Access
To facilitate switching between broadcast channels, fast-forward operation, or joining a video conference AV2 supports random access points (RAP), which are usually indicated by the presence of a key frame, which resets the decoder to its initial state. Several types of RAP in AV2 support closed GOP, open GOP, and long-term reference frames. This makes it possible to use AV2 in a variety of scenarios and support different use cases, such as streaming, broadcasting, video-conferencing, and security.
Reference frame resampling
Like AV1, AV2 allows prediction from reference frames with different resolutions on a scale from 2 to 1/16 of the current frame. This can be used to dynamically adapt video resolution to changes in network bandwidth without sending a costly key frame. This feature is useful in video conferencing while also providing foundation for scalability and switching points support.
S-frames
Streaming (like DASH) often uses chunked representations of a video at different quality levels and resolutions to adapt to changing bandwidth conditions. S-frames are inter-frames that reset arithmetic coding contexts but do not discard reference frames and can be used as low-overhead switching points. AV2 improves on AV1 by allowing reference frames to persist past an S-frame. Note that switching at an S-frame may result in a mismatch between the encoder and decoder references and consequently a quality drift. This presents a trade-off between bandwidth and quality during streaming of the same video representation or switching between rungs of the bitrate ladder, which can be used by streaming systems.
Random-access switch (RAS) frames
RAS frames are a special type of S-frames that are random access points, which can use long-term reference frames. When performing a random access at a RAS frame, long-term references need to be provided to the decoder. Random access at a RAS frame does not result in a drift unless a RAS-frame is combined with switching between different representations. Long-term reference frames may be useful in applications where a static scene need to be encoded.
Bridge frames
To facilitate efficient implementations, AV2 does not allow prediction from a frame that is more than twice higher in resolution. Bridge frames help adaptive streaming with S-frames by enabling switching to a resolution that is more than twice lower, which may be needed in case of a sudden drop in the network bandwidth. A bridge frame can be used to scale down a reference frame and can be further used for prediction, effectively allowing a greater decrease in video resolution.
Backwards Reference Update (BRU)
This tool allows partial frame updates, which enable more efficient decoding in applications where most of the frame is static, such as in screencasting.
Lossless coding
Lossless coding is still supported and has been improved compared to AV1.
Layers and sub-bitstreams
Modern decoder implementations can decode multiple bitstreams simultaneously, provided their combined complexity remains within the decoder's capabilities. AV2 goes one step further by defining multiple sub-bitstreams (also known as extended layers) within a single bitstream.
This approach benefits applications like multiview streaming, or those requiring multiple video components, such as texture and alpha channels. The specification allows to indicate how sub-bitstreams can be combined, even though implementing this combination mechanism is optional.
Each extended layer can contain multiple embedded layers, where higher embedded layers can use lower ones for prediction to provide SNR and spatial scalability. This can be used by a video conferencing engines. The specification can also efficiently support stereoscopic and multi-view video since multiple frames can be output at each time moment, and prediction between embedded layers is allowed. Temporal scalability is supported and operates orthogonally to both extended and embedded layers, and makes frame rate changes possible.
To better support spatial and SNR scalability, and long-term reference frames, AV2 can use more reference buffer slots when the frame size is smaller than the maximum allowed by the bitstream level.
At the bitstream level, Open Bitstream Units (OBU) can have 2-byte headers when they carry information about extended and embedded layers to which they belong, or 1-byte headers when only the temporal layer id is signaled. This allows an encoder to reduce the signaling overhead when spatial/SNR scalability and sub-bitstreams are not used.
Film grain synthesis
As mentioned in the previous section, the FGS support is mandatory in AV2. The AV2 FGS algorithm is very similar to the one used in AV1 and uses the same model, with some improvements related to the grain visual quality and parameters signaling, in terms of both the efficiency (along the lines of AFGS1) and modularity of FGS parameters in a video bitstream.
Metadata
AV2 specification supports a range of useful metadata underpinning various applications, including HDR metadata and user-defined metadata.
AV2 profiles, levels, tiers and interoperability points
Profiles
AV2 defines five main profiles distinguished by their support of chroma formats and interoperability points (IoP) (see Table 1). IoPs define supported combinations of extended and embedded layers (see Table 2). All current IoPs support four extended layers / sub-bitstreams but vary in terms of allowed number of embedded layers and total number of layers to match target device capabilities.
| Id | Profile name | Format | Bit depth | IoP |
|---|---|---|---|---|
| 0 | Main_420_10_IP0 | 4:0:0, 4:2:0 | 8 and 10 | 0 |
| 1 | Main_420_10_IP1 | 4:0:0, 4:2:0 | 8 and 10 | 1 |
| 2 | Main_420_10_IP2 | 4:0:0, 4:2:0 | 8 and 10 | 2 |
| 3 | Main_422_10_IP1 | 4:0:0, 4:2:0, 4:2:2 | 8 and 10 | 1 |
| 4 | Main_444_10_IP1 | 4:0:0, 4:2:0, 4:4:4 | 8 and 10 | 1 |
| 5-30 | Reserved | - | - | - |
| 31 | Configurable | 4:0:0, 4:2:0, 4:2:2, 4:4:4 | - | - |
| IoP | Num ext layers | Num emb layers | Ext+emb layers | Num layers |
|---|---|---|---|---|
| 0 | 1-4 | 1 | No | 1-4 |
| 1 | 1-4 | 1-2 | No | 1-4 |
| 2 | 1-4 | 1-3 | Yes | 1-8 |
| 3-14 | Reserved | - | - | - |
Levels and Tiers
Levels define bitstream and decoder capabilities in terms of limits on frame resolution, frame rate, and the encoded stream bitrate, scaling up to level 8.3 (supporting 30720x17280 @ 120fps). Applications can choose between two Tiers, with Main Tier intended for standard consumer delivery and High Tier for high-bitrate capture, archiving, or data-center applications.
In case of multiple sub-bitstreams, Multi Stream Decoder Operation (MSDO) OBU can indicate combined bitstream level resources to be split unequally between sub-bitstreams. For example, “large” sub-bitstream may be allocated 2/3 of the overall level resources, while up to three sub-bitstreams may be allocated each 1/9 of the resources. Alternatively, the resources can be allocated equally between sub-bitstreams. This provides flexibility of fitting sub-bitstreams into a level matching common decoder implementations.
What's next
This post has given you a brief glimpse into the AV2 codec capabilities and architecture. For more information, stay tuned for publications from the AV2 contributors, which are coming soon.
The specification is finalized now, and practical implementations are expected to follow. For an early SW-decoder preview, you can check the dav2d decoder project.
Acknowledgment
The AV2 specification and SW represent work of multiple engineers. You can see the full list of AVM contributors here, which also includes contributors to AV1 and even earlier generations of video codecs. Congratulations to everyone for reaching this milestone! Of course, this work would not have been possible without support from AOMedia companies and university labs who backed the research and development efforts their engineers spent to create AV2.